Deep Dive into Site Isolation (Part 1)
Back in 2018, Chrome enabled Site Isolation by default, which mitigates attacks such as UXSS and Spectre. At the time, I was actively participating in the Chrome Vulnerability Reward Program, and I was able to find 10+ bugs in Site Isolation, resulting in $32k rewards.
In this blog post series, I will explain how Site Isolation and related security features work, as well as explain the bugs found in those security features that have since been patched.
Methodology
In my approach for bug hunting for Chrome, I would usually start with manual testing rather than code audit. This is because the Chrome team is generally good at code reviews. So I think that most of the logical bugs that slip through their code reviews are difficult to find by code audit. Therefore, I followed the same methodology when I began looking at Site Isolation.
What is Site Isolation?
Site Isolation is a security feature that separates web pages from each Site to its own process. With Site Isolation, the boundary of a Site is aligned with OS-level process isolation, instead of in-process logical isolation, such as same-origin policy.
Site is defined as Scheme and eTLD+1 (also known as Schemeful same-site).
https://www.microsoft.com:443/
The definition of Site is broader than Origin, which is Scheme, Host, and Port.
https://www.microsoft.com:443/
 {width=”370” height=”300”}
{width=”370” height=”300”}
 {width=”370” height=”300”}
{width=”370” height=”300”}
However, not all cases fit into the above definition of a Site. So I started testing the following edge-cases to see how Site Isolation behaves in each case 😊
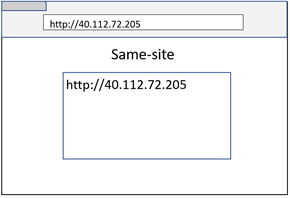
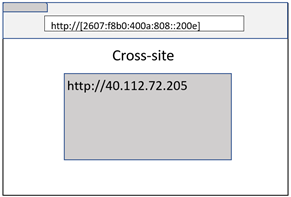
URL without a domain name
URLs are not required to contain a domain name (e.g. IP address). In this case, Site Isolation falls back to origin comparison for process isolation.
File URL
Local files can be rendered into a browser tab with the file scheme. Currently, Site Isolation treats any URL with the file scheme as originating from the same-site.


Data URL
While a Data URL loaded on the top frame is always isolated to its own process, a Data URL loaded inside an iframe will inherit the Site from the navigation initiator (even though the origin remains an opaque origin). If you are old enough, you would remember similar concept where Data URL inside an iframe used to inherit the origin in Firefox 😊
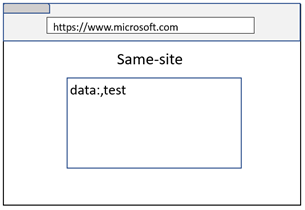

As you can see in above images, even though both examples result in microsoft.com embedding a Data URL iframe, the cross-site case remains process isolated because the navigation initiator was evil.example.
A bug in Data URL Site inheritance
What happens if a browser or a tab is restored from the local cache? Will Site Isolation still remember the navigation initiator of a Data URL, or will it forget?
It turns out that Site Isolation can’t remember the navigation initiator after a browser or a tab restore. And when a tab was restored from local cache, Site Isolation used to blindly put the Data URL within the same-site of the parent frame. An attacker could have triggered a browser crash and then restoring the browser would cause a Site Isolation bypass 😊

This bug was fixed by isolating the Data URL into a different process when the page is restored from the local cache.
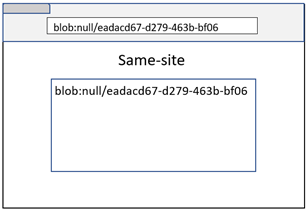
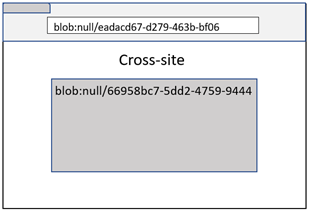
Blob URL with opaque origin
When a Blob URL is created from an opaque origin (e.g. Data URL, sandboxed iframe, or File URL), the Blob URL would look like “blob:null/[GUID]”.
Because this is a URL without a domain name, Site Isolation used to fall back to origin comparison. However, this was a bug because a Blob URL with an opaque origin can be created from a different Site. And the origin comparison wouldn’t be enough because the origin will always be “blob:null”. Therefore, this URL requires the comparison of both origin and path for process isolation.
Testing process isolation logic
I was able to find some bugs in the process isolation logic of Site Isolation using tools such as the Chromium Task Manager (Shift + Esc on Windows) and FramesExplorer, which helps identify those frames which share a process (additionally, you can also use chrome://process-internals/#web-contents).
How does Site Isolation mitigate UXSS?
Historically, Most of UXSS bugs were achieved by bypassing the same-origin policy check that is mostly implemented in a renderer process. In other words, once you can bypass the same-origin policy check, all the cross-site data was available within the renderer process. Therefore, JS code was able to get window, document, or any other cross-origin object references.
Site Isolation fundamentally changed this by process isolation. Even if you can bypass the same-origin policy check, other site’s data won’t be available in the same process.
Additionally, a UXSS vector where a cross-origin window is navigated to a JavaScript URL isn’t an issue either. This is because JavaScript URL navigation should only succeed if 2 web pages are of the same origin. Therefore, navigation to JavaScript URLs can be handled within the renderer process (which should host any same-origin pages that have window reference), and any JavaScript URL navigation request that goes up to the browser process can be safely ignored. Of course, if you forget to ignore a JavaScript URL in the browser process, that’s a bug (which was found by @SecurityMB)😉
Process Isolation isn’t enough
Site Isolation helps mitigate UXSS, however process isolation isn’t enough to protect all cross-site data from leaking.
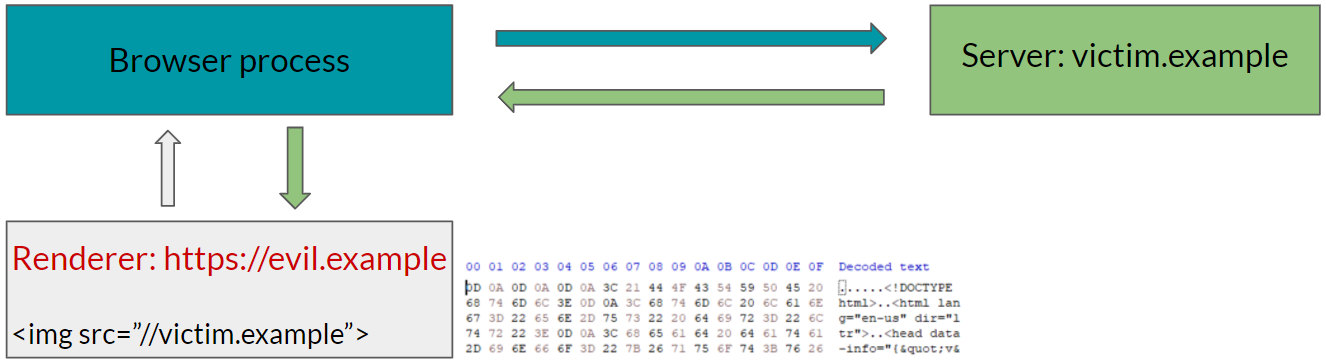
The easiest example of this is the Spectre attack. With Spectre, an attacker can read a process’s entire address space. While process isolation helps isolate web pages, subresources such as image, audio, video, etc, are not process isolated.
Therefore, without another mitigation, an attacker can read an arbitrary cross-site page by embedding that page using img tag.
Cross-Origin Read Blocking
Cross-Origin Read Blocking (CORB) mitigates the risk of exposing sensitive cross-origin data by checking MIME type of responses in cross-origin subresources. If the MIME type of cross-origin subresouces is in a deny list (e.g. HTML, XML, JSON, etc), the response will not be sent to the renderer process by default, and therefore it won’t be readable using a Spectre attack.

CORB Bypasses
There have been multiple CORB bypasses in the past.
Fundamentally, CORB can be bypassed if the URL was fetched using URLLoader with CORB disabled, and the response was leaked to a cross-site web renderer process.
For example, I was able to bypass CORB using AppCache because the URLLoader that was used to download resources for caching had CORB disabled. I knew that AppCache used to allow the caching of cross-origin HTML files, so I figured this might bypass CORB, and it did 😊
It’s also important to note that some renderer processes can bypass CORB by design (e.g. extension renderer process).
Cross-Origin Resource Policy
While CORB can protect many sensitive resources by default, some resources such as images can be embedded across sites on the Web. Therefore, CORB can’t protect such resources from entering a cross-origin page by default.
Cross-Origin Resource Policy (CORP) allows developers to indicate if a specific resource can be embedded to same-origin, same-site, or cross-origin pages. This indication allows a browser to protect resources that can’t be protected by CORB by default.

With CORP, websites can protect sensitive resources from attacks such as Spectre, XSSI, SOP bypasses specific to subresources, and so on. In other words, sensitive resources that lack a CORP header can be read using a Spectre attack (unless the resources are protected by CORB).
How to test CORB
If you have an idea on how to bypass CORB where you can load a subresource (e.g. CORB bypass via AppCache above), try to load that subresource with following response headers:
1
2
Content-Type: text/html
X-Content-Type-Options: nosniff
CORB should block such a cross-origin subresource, and therefore if the subresource was correctly loaded, that indicates a CORB bypass.
If you have an idea where subresources can’t be loaded (e.g. CORB bypass via WebSocket above), try using WinDbg’s !address command to find if the string you are looking for has actually entered into the renderer process by searching that string in a heap.
1
!address /f:Heap /c:"s -a %1 %2 \"secret\""
This searches string secret in heap memory of the renderer process. If you are looking for a unicode string instead of an ascii string, you can change -a to -u (more details in the search memory section).
What’s next?
With Site Isolation, CORB, and CORP, we can mitigate many attacks from UXSS to Spectre along with many other client-side attacks, which allow an attacker to read cross-site information. However, there are attacks which can fully compromise a renderer process. The next part will focus on how Site Isolation was further tightened to mitigate such an attacker from obtaining cross-site information.