Using Markov Models for Password Complexity Estimation in Microsoft Edge
Despite recent advancements in adoption of passkeys, passwords remain one of the most widely used authentication mechanisms on the web, yet repeated studies have demonstrated that humans are particularly bad at generating them. Chromium (the open-source project that Edge and Chrome are based upon) uses a library called “zxcvbn” created by Dropbox to perform strength estimation, and you may have seen a dialog box such as this while creating login credentials in Edge [figure 1]. 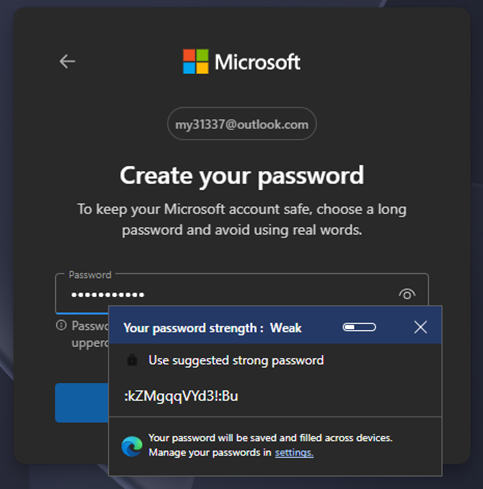 FIGURE 1: PASSWORD STRENGTH & SUGGESTION DIALOG
FIGURE 1: PASSWORD STRENGTH & SUGGESTION DIALOG
In this article, I will share why we revisited password strength estimation in Microsoft Edge, what we learned from analysing today’s password habits, and how a Markov model-based estimator can offer a practical improvement in accuracy and efficiency.
To understand why we revisited this problem, it is useful to first look at how the existing estimator works, what trade-offs it makes, and how modern attackers approach password guessing.
What a password strength estimator is (and isn’t)
A password strength indicator is a user experience feature: it tries to steer people away from passwords that are likely to be guessed quickly, and towards passwords that are more complex. It is not a proof of security, it can’t validate whether a password has been reused elsewhere, and it can’t model every attacker or every guessing strategy. What it can do is provide a consistent, privacy-preserving, on-device estimate that’s “good enough” to encourage better choices at the moments that matter (account creation and password change).
Chromium’s existing estimator: fast, practical, and widely used.
The Chromium project has long used zxcvbn, an open-source password strength estimator originally created by Dropbox. zxcvbn’s design goal is very pragmatic: recognise common patterns that humans use (dictionary words, names, keyboard patterns, predictable substitutions, repeated sequences, etc.) and translate those into an estimate of how many guesses an attacker might need to discover the password. It has the benefit of being well-understood, well-tested in the ecosystem, and it does a good job of identifying many of the most common “obviously weak” choices that users make.
That said, our research suggested some inherent trade-offs in an approach that leans heavily on curated dictionaries and hand-written matching rules. Dictionaries can reflect the languages and cultures they were built from, and keeping lists representative over time is difficult. There are also practical limitations of shipping large collections of real-world breached passwords in a browser. None of these issues make zxcvbn “wrong”; they’re the result of sensible engineering choices made under real product constraints.
Analysis of the existing solution
While zxcvbn has proven to be a fine solution, our analysis highlighted several structural limitations that emerge once you look at large, realworld password datasets.
1. Reliance on curated wordlists introduces unavoidable bias
At its core, zxcvbn relies on matching substrings against a set of curated dictionaries (common passwords, names, words, etc.), combined with handwritten rules to account for transformations such as leetspeak or capitalization.
This dependence on word lists inevitably introduces a bias that reflects the language and cultural context in which they were assembled. In the case of zxcvbn, the provided datasets are overwhelmingly biased toward US English, incorporating English Wikipedia ngrams, US census names, and US film and television references.
This bias can lead to materially different strength assessments for semantically equivalent passwords expressed in different languages. For example, the English phrase “iloveyou” is present in bundled dictionaries and is correctly identified as a highly predictable password. The German equivalent “ichliebedich,” however, does not appear in these wordlists and is therefore treated as an unstructured string, receiving a significantly higher strength score despite offering no additional resistance to guessing attacks.
This discrepancy does not reflect a meaningful difference in attacker effort, but rather a limitation of the dictionary coverage. Expanding wordlists to address this issue introduces additional challenges: increased on-disk footprint, higher update frequency, and ongoing maintenance burden as languages, dialects, and cultural references evolve. As a result, dictionary-based estimators tend to conflate linguistic familiarity with predictability, systematically overestimating strength for underrepresented languages.
It is neither practical nor desirable to ship exhaustive lists of real-world breached passwords in a browser. As a result, any wordlist based approach must select a subset, which inevitably means that many weak but less common passwords will not be recognised.
2. Diminishing wordlist relevance
Our study identified that the stock wordlists provided by the zxcvbn project do include several references to western Film and Television. This represents patterns that we can observe in human-generated passwords wherein the user’s favourite movies, actors, songs, bands, etc are used as the basis for the password.
However, the wordlists represent a snapshot of the cultural zeitgeist at the point where they were created (the wordlists provided in the zxcvbn repository, for example were last updated in 2015). To put that in perspective, Netflix only began creating original content in 2013 and many of today’s streaming services like Disney+ were created over the course of the pandemic in 2019 onwards.
3. Static rules struggle to model how humans compose passwords
In addition to the wordlists, zxcvbn’s matcher pipeline is built around a collection of explicit rules: spatial keyboard walks, repeated substrings, and predictable mutations. While these rules are effective at catching many obvious cases, they are necessarily enumerative. Our research observed that:
- Human chosen passwords often emerge from combinations of partial patterns rather than clean dictionary words (for example, fragments, overlaps, or blended constructions).
- Capturing these behaviours with explicit rules quickly becomes complex and brittle, and expanding coverage requires adding more special case logic over time.
In contrast, attackers performing password guessing do not rely on such rules; they rely on probabilistic models learned directly from password data. This asymmetry means rule-based estimators can diverge from real-world guessing efficiency as attacker tooling evolves.
Attacker Reality: How Password Guessing Works in Practice
When assessing password strength, it is important to be explicit about the threat model the estimator is attempting to approximate. In both online and offline scenarios, modern attackers do not rely on adhoc rules or manual intuition when attempting to recover credentials. Instead, password guessing is optimized around ordering guesses by likelihood, with the goal of recovering the correct password in the minimum number of attempts.
Contemporary password recovery tools such as Hashcat and John the Ripper prioritize guesses using probabilistic techniques trained on large collections of real-world breached passwords. These tools do not attempt to enumerate all possible strings uniformly. Instead, they model the statistical structure of human chosen passwords and explore the most likely regions of the password space first. As a result, passwords that appear superficially complex may still be recovered quickly if they align with common character sequence patterns observed in breached data.
This distinction matters because a password strength estimator embedded in a browser is not attempting to predict user intent or enforce arbitrary composition rules. Its purpose is to approximate the realworld effort required for an attacker to guess a given password under realistic constraints. Any estimator that diverges significantly from attacker behaviour risks either overstating strength or failing to warn users about credentials that are practically guessable.
This observation motivates the exploration of probabilistic models—already used extensively by attackers themselves—as a basis for password strength estimation.
A different approach: learning character-sequence likelihood with Markov models
Considering our findings, the Edge security team proposed a different approach using Markov models. Instead of trying to recognise specific words or patterns from large lists, a Markov-model estimator looks at something more fundamental: given starting character Ci, what is the most likely value of Ci+1 based on what we see in real-world password leaks? In simple terms, it learns which character pairs (or n-grams) are common (for example, “pa”, “ss”, “wo”, “rd”) and which are rare (“JT”, “ZB”, etc). A password made from very common sequences is more likely to have been chosen by a human (and therefore more likely to be guessed quickly), while a password made from unusual sequences looks closer to a random string.
Concretely, the estimator assigns a probability to a password by multiplying the probabilities of its character transitions; we then convert that probability into a more usable score by taking its logarithm. We can then loosely map score ranges into user-friendly buckets (for example, very weak → very strong) and tune those thresholds using empirical data. This is similar in spirit to techniques used in password recovery tooling, but in Edge the model is used locally to inform the strength indicator without sending your password anywhere.
One of the reasons we like this approach is that it tends to generalise better: it doesn’t need to “know” a specific word to judge that it looks like a human-chosen phrase. That helps reduce dependence on any single language’s dictionary coverage.
Empirical comparison of approaches
To better understand how different estimator designs behave on real-world data, we evaluated both zxcvbn and our Markov based estimator against infamous “RockYou” dataset that is commonly used in password recovery research. This wordlist is well understood in the security community and represents passwords that are routinely recovered quickly by modern attack tooling.
The goal of this comparison is not to declare a single “correct” strength score for any given password, but to examine how the underlying modelling assumptions of each estimator affect weak passwords classification in aggregate.
When evaluated side by side, a notable divergence emerges [Table 1]. The Markov-based estimator assigns a larger proportion of leaked passwords to the lowest strength buckets, whereas zxcvbn distributes many of the same passwords across higher categories. This difference is not the result of implementation errors in either system, but a consequence of the signals each model is designed to capture.
| Score | Description | Number of Passwords with Score | |||
|---|---|---|---|---|---|
| zxcvbn | Markov | ||||
| 0 | Very Weak | 15602 | 1.56% | 766077 | 76.61% |
| 1 | Weak | 730451 | 73.05% | 231942 | 23.19% |
| 2 | Moderate | 195343 | 19.53% | 1607 | 0.16% |
| 3 | Strong | 49954 | 4.99% | 269 | 0.03% |
| 4 | Very Strong | 8650 | 0.86% | 105 | 0.01% |
Note that all zxcvbn data discussed was captured using the python library and the default dictionaries.
Concrete examples help illustrate this effect. Taking the previous example, we see that zxcvbn correctly identifies the password “iloveyou” as a highly predictable password, assigning it the lowest score. Whereas it assigns equivalent German phrase “ichliebedich” a much higher strength score. In contrast, the Markov-based estimator assigns similarly low scores to both inputs, reflecting the fact that both exhibit character sequence patterns that are common in human chosen passwords.
Conversely, certain patterns such as long, predictable sequences display the opposite behaviour. Zxcvbn correctly scores the alphabet “abcdefghijklmnopqrstuvwxyz” as low and predictable, where our model gave it a high score.
| Input | zxcvbn | Markov |
|---|---|---|
| "iloveyou" | Very Weak | Very Weak |
| "ichliebedich" | Strong | Weak |
| "abcdefghjik…rstuvwxyz" | Very Weak | Very Strong |
More broadly, this comparison highlights how dictionary and rulebased estimators tend to reward novelty relative to their curated datasets, whereas probabilistic models reward rarity relative to observed password composition as a whole. Neither approach is universally superior; they make different tradeoffs in how closely their output tracks the practical effort required to guess passwords drawn from realworld distributions.
Conclusion
Password strength estimation is an imperfect science, and different approaches make different trade-offs. On balance, we believe the Markov approach is a slight improvement for users, while also being significantly more efficient for the browser. The current version of our model is smaller than the existing dictionary-based data sets (hundreds of kilobytes, rather than multiple megabytes). That translates into reduced disk footprint, reduced memory pressure, performance gains, and lower distribution overhead. Starting in Edge 147, we began rolling out our new Markov model-based implementation. The user experience is intentionally familiar: you’ll still see the same kind of strength feedback when generating or entering a new password. What changes is the engine behind the scenes. The new library is written in Rust for memory safety and performance. The library will eventually be open-sourced and available for use in other projects. We’ll continue to evaluate the estimator in the field and refine it over time, but we’re optimistic that this is a modest step forward both for user guidance and for browser efficiency.